
This put up is a part of our Scaling Kubernetes Sequence. Register to look at stay or entry the recording.
Lowering infrastructure prices boils right down to turning sources off once they’re not being utilized. Nevertheless, the problem is determining how one can flip these sources on robotically when obligatory. Let’s run by way of the required steps to deploy a Kubernetes cluster utilizing Linode Kubernetes Engine (LKE) and use the Kubernetes Occasions-Pushed Autoscaler (KEDA) to scale to zero and again.
Why Scale to Zero
Let’s think about you might be operating a fairly resource-intensive app on Kubernetes and it’s solely wanted throughout work hours.
You may wish to flip it off when folks go away the workplace and again on once they begin the day.
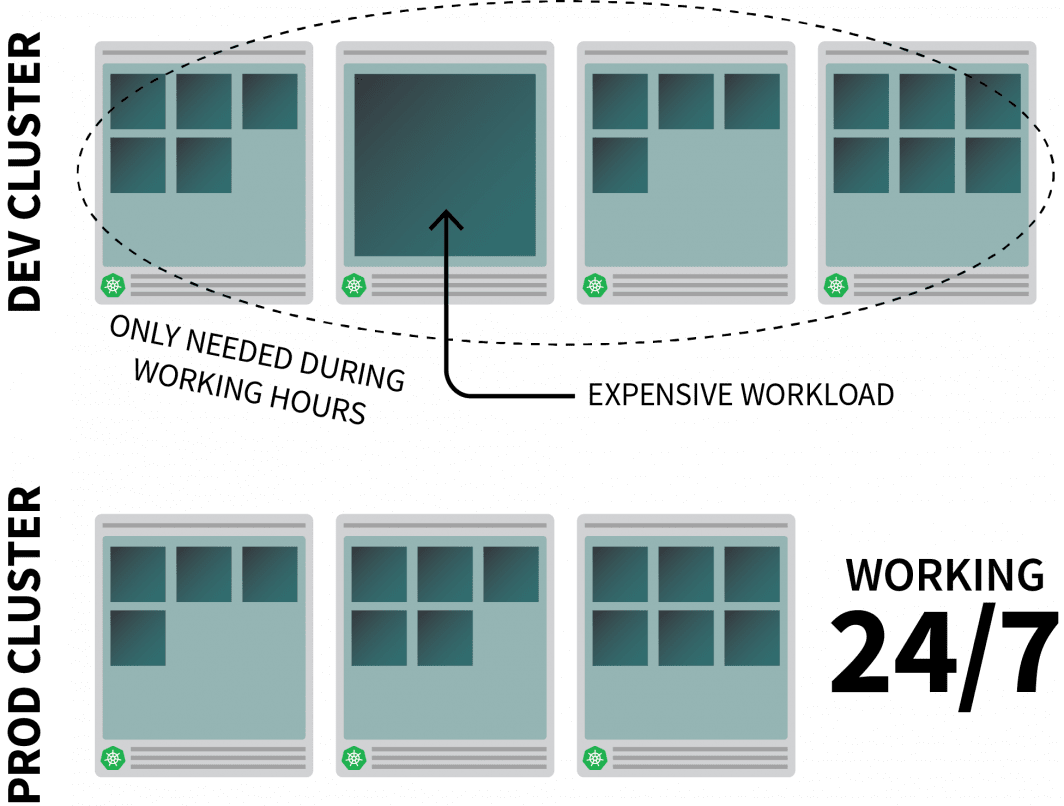
When you may use a CronJob to scale up and down the occasion, this resolution is a stop-gap that may solely run on a pre-set schedule.
What occurs through the weekend? And what about public holidays? Or when the staff is off sick?
As a substitute of producing an ever-growing listing of guidelines, you’ll be able to scale up your workloads primarily based on visitors. When the visitors will increase, you’ll be able to scale the replicas. If there isn’t any visitors, you’ll be able to flip the app off. If the app is switched off and there’s a brand new incoming request, Kubernetes will launch no less than a single duplicate to deal with the visitors.

Subsequent, let’s speak about how one can:
- intercept all of the visitors to your apps;
- monitor visitors; and
- arrange the autoscaler to regulate the variety of replicas or flip off the apps.
When you want to learn the code for this tutorial, you are able to do that on the LearnK8s GitHub.
Making a Cluster
Let’s begin with making a Kubernetes cluster.
The next instructions can be utilized to create the cluster and save the kubeconfig file.
bash
$ linode-cli lke cluster-create
--label cluster-manager
--region eu-west
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id right here" --text | tail +2 | base64 -d > kubeconfigYou possibly can confirm that the set up is profitable with:
bash
$ kubectl get pods -A --kubeconfig=kubeconfigExporting the kubeconfig file with an surroundings variable is normally extra handy.
You are able to do so with:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsNow let’s deploy an software.
Deploy an Utility
yaml
apiVersion: apps/v1
form: Deployment
metadata:
identify: podinfo
spec:
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- identify: podinfo
picture: stefanprodan/podinfo
ports:
- containerPort: 9898
---
apiVersion: v1
form: Service
metadata:
identify: podinfo
spec:
ports:
- port: 80
targetPort: 9898
selector:
app: podinfoYou possibly can submit the YAML file with:
terminal|command=1|title=bash
$ kubectl apply -f 1-deployment.yamlAnd you may go to the app with:
Open your browser to localhost:8080.
bash
$ kubectl port-forward svc/podinfo 8080:80At this level, it is best to see the app.
Subsequent, let’s set up KEDA — the autoscaler.
KEDA — the Kubernetes Occasion-Pushed Autoscaler
Kubernetes presents the Horizontal Pod Autoscaler (HPA) as a controller to extend and reduce replicas dynamically.
Sadly, the HPA has a number of drawbacks:
- It doesn’t work out of the field– it is advisable set up a Metrics Server to combination and expose the metrics.
- It doesn’t scale to zero replicas.
- It scales replicas primarily based on metrics, and doesn’t intercept HTTP visitors.
Happily, you don’t have to make use of the official autoscaler, however you need to use KEDA as a substitute.
KEDA is an autoscaler fabricated from three elements:
- A Scaler
- A Metrics Adapter
- A Controller
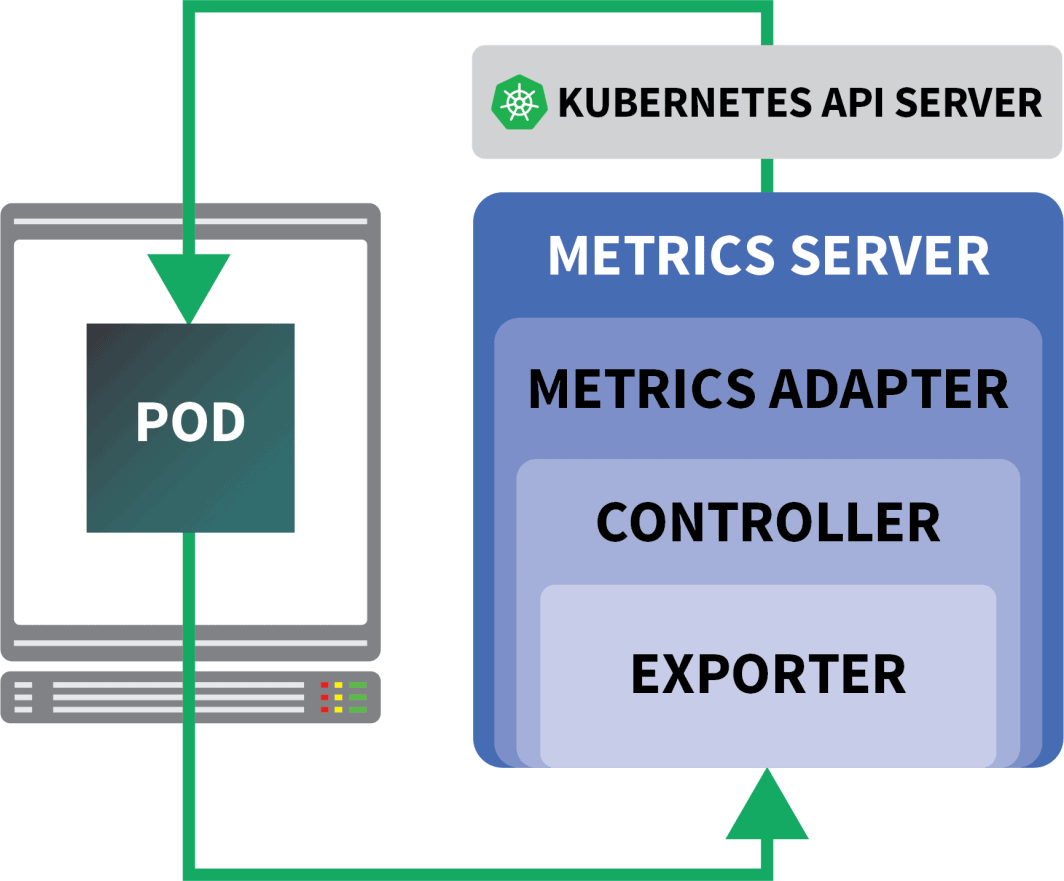
Scalers are like adapters that may gather metrics from databases, message brokers, telemetry techniques, and so on.
For instance, the HTTP Scaler is an adapter that may intercept and gather HTTP visitors.
You could find an instance of a scaler utilizing RabbitMQ right here.
The Metrics Adapter is liable for exposing the metrics collected by the scalers in a format that the Kubernetes metrics pipeline can devour.
And at last, the controller glues all of the elements collectively:
- It collects the metrics utilizing the adapter and exposes them to the metrics API.
- It registers and manages the KEDA-specific Customized Useful resource Definitions (CRDs) — i.e. ScaledObject, TriggerAuthentication, and so on.
- It creates and manages the Horizontal Pod Autoscaler in your behalf.
That’s the idea, however let’s see the way it works in follow.
A faster solution to set up the controller is to make use of Helm.
You could find the set up directions on the official Helm web site.
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm set up keda kedacore/kedaKEDA doesn’t include an HTTP scaler by default, so you’ll have to set up it individually:
bash
$ helm set up http-add-on kedacore/keda-add-ons-httpAt this level, you might be able to scale the app.
Defining an Autoscaling Technique
The KEDA HTTP add-on exposes a CRD the place you’ll be able to describe how your software needs to be scaled.
Let’s take a look at an instance:
yaml
form: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
identify: podinfo
spec:
host: instance.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10This file instructs interceptors to ahead requests for instance.com to the podinfo service.
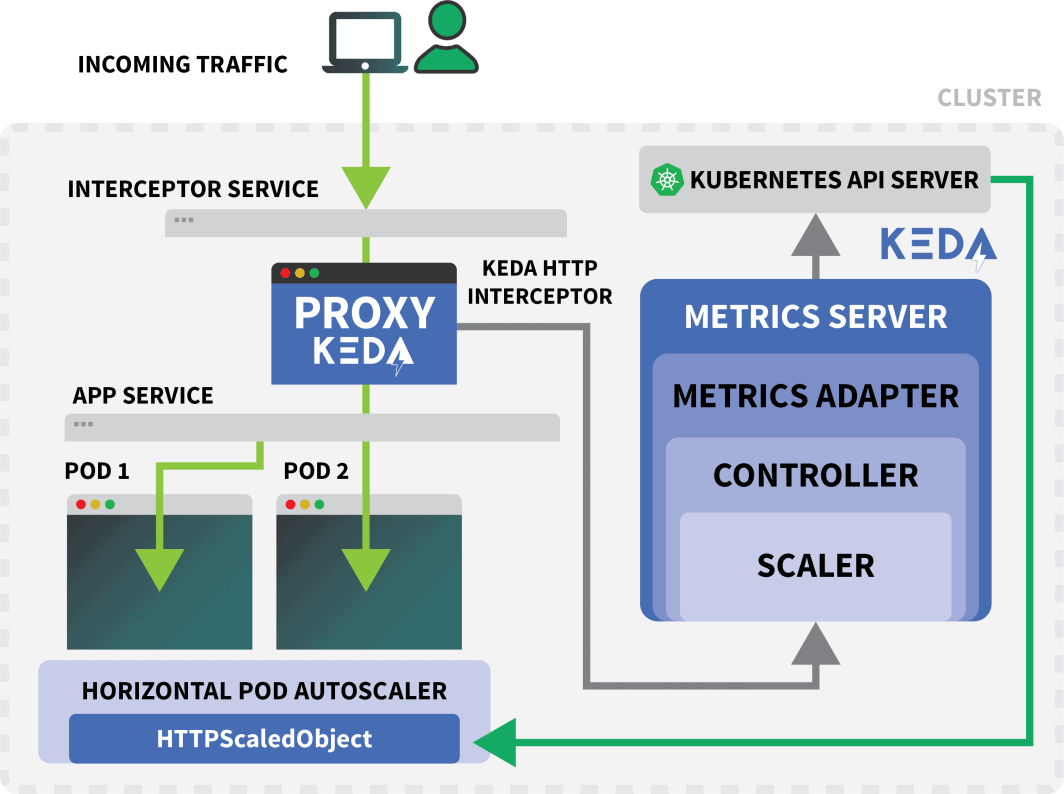
It additionally contains the identify of the deployment that needs to be scaled — on this case, podinfo.
Let’s submit the YAML to the cluster with:
bash
$ kubectl apply -f scaled-object.yamlAs quickly as you submit the definition, the pod is deleted!
However why?
After an HTTPScaledObject is created, KEDA instantly scales the deployment to zero since there’s no visitors.
You could ship HTTP requests to the app to scale it.
Let’s check this by connecting to the service and issuing a request.
bash
$ kubectl port-forward svc/podinfo 8080:80The command hangs!
It is smart; there aren’t any pods to serve the request.
However why is Kubernetes not scaling the deployment to 1?
Testing the KEDA Interceptor
A Kubernetes Service referred to as keda-add-ons-http-interceptor-proxy was created while you used Helm to put in the add-on.
For autoscaling to work appropriately, the HTTP visitors should route by way of that service first.
You should use kubectl port-forward to check it:
shell
$ kubectl port-forward svc/keda-add-ons-http-interceptor-proxy 8080:8080This time, you’ll be able to’t go to the URL in your browser.
A single KEDA HTTP interceptor can deal with a number of deployments.
So how does it know the place to route the visitors?
yaml
form: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
identify: podinfo
spec:
host: instance.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10The HTTPScaledObject has a bunch discipline that’s used exactly for that.
On this instance, faux the request comes from instance.com.
You are able to do so by setting the Host header:
bash
$ curl localhost:8080 -H 'Host: instance.com'You’ll obtain a response, albeit with a slight delay.
When you examine the pods, you’ll discover that the deployment was scaled to a single duplicate:
bash
$ kubectl get podsSo what simply occurred?
While you route visitors to the KEDA’s service, the interceptor retains observe of the variety of pending HTTP requests that haven’t had a reply but.
The KEDA scaler periodically checks the scale of the queue of the interceptor and shops the metrics.
The KEDA controller displays the metrics and will increase or decreases the variety of replicas as wanted. On this case, a single request is pending — sufficient for the KEDA controller to scale the deployment to a single duplicate.
You possibly can fetch the state of a person interceptor’s pending HTTP request queue with:
bash
$ kubectl proxy &
$ curl -L localhost:8001/api/v1/namespaces/default/providers/keda-add-ons-http-interceptor-admin:9090/proxy/queue
{"instance.com":0,"localhost:8080":0}Resulting from this design, you should be cautious the way you route visitors to your apps.
KEDA can solely scale the visitors if it may be intercepted.
You probably have an current ingress controller and want to use that to ahead the visitors to your app, you’ll have to amend the ingress manifest to ahead the visitors to the HTTP add-on service.
Let’s take a look at an instance.
Combining the KEDA HTTP Add-On with the Ingress
You possibly can set up the nginx-ingress controller with Helm:
bash
$ helm improve --install ingress-nginx ingress-nginx
--repo https://kubernetes.github.io/ingress-nginx
--namespace ingress-nginx --create-namespaceLet’s write an ingress manifest to route the visitors to podinfo:
yaml
apiVersion: networking.k8s.io/v1
form: Ingress
metadata:
identify: podinfo
spec:
ingressClassName: nginx
guidelines:
- host: instance.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
identify: keda-add-ons-http-interceptor-proxy # <- this
port:
quantity: 8080You possibly can retrieve the IP of the load balancer with:
bash
LB_IP=$(kubectl get providers -l "app.kubernetes.io/element=controller" -o jsonpath="{.objects[0].standing.loadBalancer.ingress
[0].ip}" -n ingress-nginx)You possibly can lastly make a request to the app with:
bash
curl $LB_IP -H "Host: instance.com"It labored!
When you wait lengthy sufficient, you’ll discover that the deployment will finally scale to zero.
How Does This Examine to Serverless on Kubernetes?
There are a number of vital variations between this setup and a serverless framework on Kubernetes corresponding to OpenFaaS:
- With KEDA, there isn’t any have to re-architecture or use an SDK to deploy the app.
- Serverless frameworks deal with routing and serving requests. You solely write the logic.
- With KEDA, deployments are common containers. With a serverless framework, that’s not at all times true.
Wish to see this scaling in motion? Register for our Scaling Kubernetes webinar sequence.
{kind=link}